32位DSP设计中的流水线数据相关问题及解决办法
| 引言 在航空微电子中心的某预研项目中,需要开发设计某32位浮点通用数字信号处理器(DSP)。本系统控制通路部分的设计采用超级哈佛及五级流水线结构。本文分析了该流水线的设计过程,并对遇到的数据相关问题提出了一种新的解决方法。 1 流水线结构 流水线处理器一般把一条指令的执行分成几个步骤,或称为级(stages)。每一级在一个时钟周期内完成,也就是说在每个时钟周期,处理器启动并执行一条指令。如果处理器的流水线有m级,则同时可重叠执行的指令总条数为m。由于每条指令处在不同的执行阶段,因此,如果分级分得好,每一级都没有时间上的浪费,这就是最理想的情况。流水线处理器在理想情况下与非流水线处理器的性能加速比为:
式中,I为一个程序被执行的总的指令条数,它在流水线处理器和非流水线处理器中是相等的。CPInp是每条指令总体平均所需的时钟周期数。因为流水线处理器把一条指令的执行时间理想地分成了m级,故有m条指令在同时(重叠)执行。T是每个时钟周期的时间长度,本例可假设它在两种处理器中也是相同的,那么,最后总的加速比为m(即等于流水线的级数)。并不是说把流水线级数分得越多,处理器的性能就越好。流水线处理器性能提高的关键在于每个时钟周期处理器都应当能启动一条指令的执行。
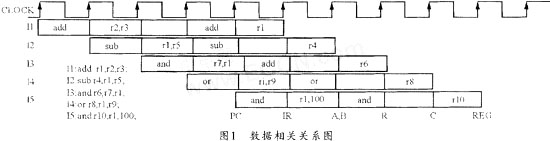
在上述程序段中,I1指令把寄存器r2和r3的内容相加,并将结果存人寄存器r1,这样,它下面的4条指令均与I1相关,其使用I1的结果如图1给出的数据相关关系图。从图中可见,当每个周期结束时,在时钟上升沿应把数据打入寄存器。在数据没被打入之前,任何从该寄存器读出的数据都是过时的。图1中的I2到I4的3条指令就属于这种情况。它们从r1寄存器读出的数据都是过时的,是不能使用的。I5则没关系,当它读r1寄存器时,I1已将结果写入。
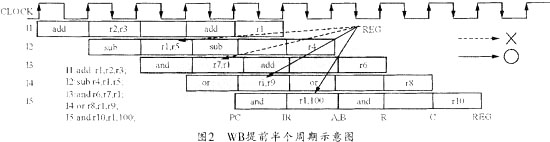
I1下面有3条指令不能从寄存器r1读出正确的数据。为了减少数据相关指令的条数,设计时可以让写寄存器堆的操作提前半个周期,即由时钟的下降沿打入。实践证明这样做是可行的,因为假定一个时钟周期是10 ns,寄存器堆的访问只需要5 ns。这样,数据相关的指令条数就减至两条,其操作示意图如图2所示。
3 数据相关问题的解决
由于一条指令中的两个源操作数都可能与上一条指令的目的操作数相关,因此,总的数据相关DEPEN由A DFPEN和B_DEPEN两部分组成。A_DEPEN指的是源寄存器rs1数据相关,B_DE-PEN指的是源寄存器rs2数据相关。另外,两条指令I2和I3也都可能与I1相关。如果是在流水线ID级检测数据相关,那么,对于I2来讲,I1处在EXE级;对于I3来讲,I1处在MEM级,因此,A_DEFPEN包括EXE_A_DEPEN和MEM_B_DEPEN两部分。EXE_A_DEPEN的意思是处在ID级的指令与处在EXE级的指令数据相关。同理,MEM_A_DEPEN的意思是处在ID级的指令与处在MEM级的指令数据相关。同样,B_DEPEN也包括EXE_B_DEPEN和MEM_B_DEPEN两部分。 EXE_A_DEPEN为真的条件是:I2的rs1与I1的rd相等(ID_rs1==EXE_rd),rs1字段是寄存器(ID_rs1IsReg),并且I1的rd确实是目的寄存器(EXE_WREG==1)。后一个条件是为排除store指令而加上的。EXE_B_DEPEN与EXE_A_DEPEN类似,源寄存器号(ID_rs2IsReg)所包含的指令要比ID_rs1IsReg少得多。I3与I1的数据相关判断与此类似。
(1) 封锁当前正译码的指令的写控制信号; |